ORACLE 使用与慢查询分析
表空间和用户赋权
创建用户,用户名一般是工程名或者能标识一个工程的名称。例如cbbank-athena工程:
create user athena identified by athena
grant connect,resource,dba to athena /*按需分配权限*/创建表空间和索引空间,表空间格式d_用户名,索引空间格式i_用户名:
/*表空间*/
create tablespace d_athena
logging
datafile '/home/oracle/app/d_athena.dbf'
size 50m
autoextend on
next 50m maxsize 20480m
extent management local;
/*索引空间*/
create tablespace i_athena
logging
datafile '/home/oracle/app/i_athena.dbf'
size 50m
autoextend on
next 50m maxsize 20480m
extent management local;SEQUENCE
CACHE、CYCLE、NOORDER三项为必选参数
--创建 SEQUENCE
CREATE SEQUENCE athena.config_seq
INCREMENT BY 1 /*每次增量*/
START WITH 10000 /*开始的值*/
MINVALUE 10000 /*最小值*/
MAXVALUE 999999999 /*最大值*/
CACHE 1000 /*预生成序列*/
CYCLE /*是否循环*/
NOORDER; /*是否按请求顺序分配,用了CACHE后就是NOORDER*/
-- 更新序列
alter sequence athena.config_seq
maxvalue 999999999
increment by 11
CACHE 5000
cycle
NOORDER;
-- 删除序列
drop sequence athena.config_re表操作
--创建表
CREATE TABLE athena.config
(
id number(19) not null,
service number(19),
type varchar2(60)
) tablespace d_athena;
-- 增加主键
alter table athena.config add constraint pk_config primary key (id) using index tablespace i_athena;
-- 增加唯一索引要先创建索引再创建唯一约束
create index i_config_service_type on athena.config(service,type) tablespace i_athena;
alter table athena.config add constraint uni_config_service unique(service);
-- 给表和字段增加注释
comment on table athena.config is '微服务API附加配置表'
comment on column athena.config.id is '唯一编号'
comment on column athena.config.service is 'service编号'
comment on column athena.config.type is '类型'
分区表操作
分区表可以根据实际需求按时间或者id。
分区表不推荐建立主键以外的全局索引
-- 建表
CREATE TABLE athena.flow
(
id number(19) not null,
trace_id number(19),
channel_no varchar2(60),
create_time timestamp
) PARTITION BY RANGE (create_time)(
PARTITION flow_202104 VALUES LESS THAN (to_timestamp('2021-04-01 00:00:00','yyyy-MM-dd hh24:mi:ss')),
PARTITION flow_202105 VALUES LESS THAN (to_timestamp('2021-05-01 00:00:00','yyyy-MM-dd hh24:mi:ss'))
)TABLESPACE d_athena;
-- 创建全局主键
alter table athena.flow add constraint pk_flow primary key (id) using index tablespace i_athena;
-- 创建分区索引,需要带上local才是分区索引
create index i_flow_create_time on athena.flow(create_time) local tablespace i_athena;
-- 新增分区
ALTER TABLE athena.flow ADD PARTITION flow_202106 VALUES LESS THAN (to_timestamp('2021-06-01 00:00:00','yyyy-MM-dd hh24:mi:ss'));ORACLE 使用与慢查询分析
- 查询全部数据,生产代码禁止使用全量查询。执行计划走的是全表,根据id从大到小执行。
-- 查询全部数据,生产代码禁止使用全量查询
explain plan for select * from athena.config;
-- 显示执行计划
select * from table(dbms_xplan.display);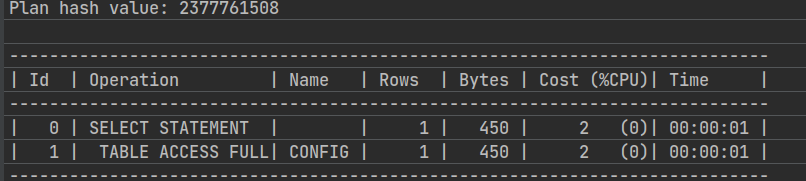
- 分区表查询全部数据,生产代码禁止使用全量查询,执行计划走的是全表全分区。
--分区表查询全量数据,生产代码禁止使用全量查询,查询必须带上分区条件
explain plan for select * from athena.flow;
select * from table(dbms_xplan.display);
- 使用索引查询
-- 索引service 查询,走的是索引
explain plan for select * from ATHENA.CONFIG where service > 1;
select * from table(dbms_xplan.display);
如果使用不等号,走的是全表
-- 索引service 不等于号
explain plan for select * from ATHENA.CONFIG where service <> 1;
select * from table(dbms_xplan.display);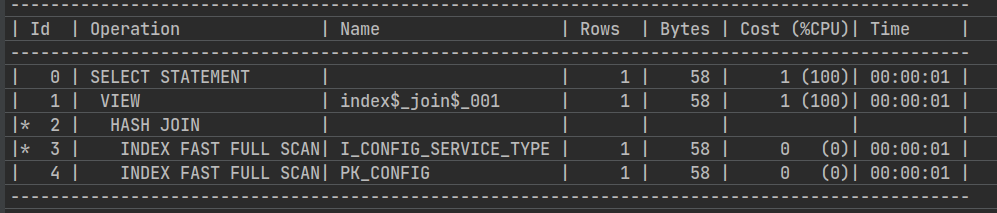
要避免在索引列上进行计算、函数、(显式/隐式)类型转换
---- 使用计算:
SELECT * FROM dept WHERE salary * 12 > 25000;
---- 函数运算:
SELECT time FROM user WHERE DATE_ADD(time, INTERVAL 7 DAY) >= now();
---- 类型转换:
SELECT * FROM staff WHERE name = 123; // name(var_char) number => var_char-- 对数字使用like,走的是全表,隐式转换
explain plan for select * from ATHENA.CONFIG where service like '1%';
select * from table(dbms_xplan.display);
- 组合索引查询,组合索引尽量使用索引的全部字段,可以缺后项,但不能缺前项。执行计划可以看到使用组合索引,缺了前项后,走的是全表。
--组合索引
explain plan for select * from ATHENA.CONFIG where service =1 and type='d';
select * from table(dbms_xplan.display);
--组合索引前项
explain plan for select * from ATHENA.CONFIG where service=1;
select * from table(dbms_xplan.display);
-- 只用组合索引后项,全表
explain plan for select * from ATHENA.CONFIG where TYPE='d'
select * from table(dbms_xplan.display);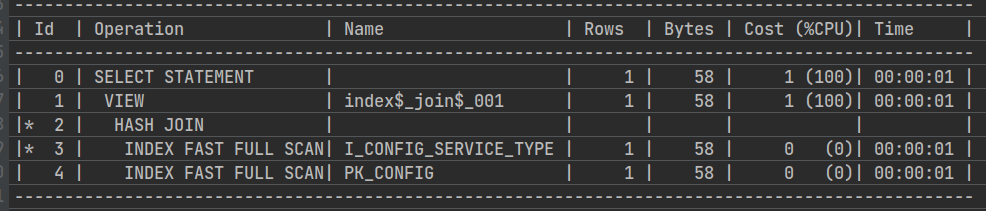
5.分区表查询时候,条件中要带上分区键
-- 分区,local索引
explain plan for select * from ATHENA.flow where create_time > to_timestamp('2021-04-01 00:00:00','yyyy-MM-dd hh24:mi:ss') and create_time < to_timestamp('2021-04-10 00:00:00','yyyy-MM-dd hh24:mi:ss');
-- 跨分区
explain plan for select * from ATHENA.flow where create_time > to_timestamp('2021-02-01 00:00:00','yyyy-MM-dd hh24:mi:ss') and create_time < to_timestamp('2021-04-10 00:00:00','yyyy-MM-dd hh24:mi:ss');
- 避免使用NOT IN 后面是大表,如果业务需要可以使用NOT EXISTS或者OUTER JOINS
-- B是个大表
SELECT * FORM A WHERE col NOT IN (SELECT col FROM B)
-- => 应该使用
SELECT * FORM A WHERE NOT EXISTS(SELECT col FROM B WHERE A.col = B.col)- 避免使用OR关联索引列和非索引列,如果业务需要就用UNION代替
-- id均为索引,age为非索引
SELECT * FROM user WHERE id = 10 or age = 20;
-- => 应该使用
SELECT * FROM user WHERE id = 10 UNION SELECT * FROM user WHERE age = 20;- 避免在索引列上使用IS NULL和IS NOT NULL ,推荐在建表时把索引列设为not null
---- 单列索引:如果列包含空值,索引中将不存在此记录。
---- 复合索引:如果每个列都为空,索引中同样不存在此记录。如果有一个列不为空,则记录存在于索引中。
SELECT * FROM department WHERE dept_code IS NOT NULL;
-- => 应该使用
SELECT * FROM department WHERE dept_code >=0;- 避免在WHERE条件中索引列使用!=或者<>,使用模糊查询时避免使用前导%,除非索引覆盖完全即所有条件和查询列均为索引。能不使用模糊查询时,尽量不使用。
SQL优化
根据需要用UNION ALL替换UNION
UNION:对结果进行排序去重;
UNION-ALL:不排序,不去重;业务场景允许的情况下使用UNION-ALL代替UNION
尽量避免使用 ,不要获取不必要的字段,将依次转换为列名时,通过查询数据字典完成,浪费时间
用EXISTS替换DISTINCT
-- 当查询中包含的表之间有一对多的关系时,避免在SELECT子句中使用DISTICT,可以使用EXISTS替换。
SELECT DISTINCT d.dept_no,d.dept_name FROM dept d,emp e WHERE d.deptno = e.deptno;
-- ==>
SELECT d.deptno,d.dname FROM dept d
WHERE EXISTS (SELECT 'X' FROM emp e WHERE e.deptno = d.deptno);- 用Where子句替换HAVING子句
-- HAVING在检索出所有记录后进行过滤,会进行排序等操作。
SELECT job, AVG(age) FROM temp GROUP BY job HAVING job = 'STUDENT' OR job = 'MANAGER';
-- ==>
SELECT job,AVG(age) FROM EMP WHERE job = 'STUDENT' OR job = 'MANAGER' GROUP BY job;在清空表内容,并且不需要恢复的情况下使用TRUNCATE更高效
合理使用EXISTS和IN
-- IN不走索引,区分三种情况:
-- 1、两张表规模在同一数量级,使用IN和使用EXISTS效率差不多;
-- 2、A大表,B小表:
SELECT * FORM A WHERE col IN (SELECT col FROM B)
-- 3、A小表,B大表:
SELECT * FORM A WHERE EXISTS(SELECT col FROM B WHERE A.col = B.col)关联大表时必须使用索引
以下情况下索引重建提高效率
-- 顺序执行以下SQL
-- 1、VALIDATE INDEX 用户名.索引名
-- 2、
SELECT name,height, del_lf_rows, lf_rows, ROUND((del_lf_rows/(lf_rows+0.0000000001))*100) "Frag Percent" FROM index_stats
-- 如果索引的叶子行的碎片(Frag Percent)>10% 或者 height > 3, 可以考虑对索引进行重建;
-- 执行以下SQL
SELECT extents FROM DBA_SEGMENTS WHERE owner='SYS' and segment_name='index_name';
-- 如果extents >10,可以考虑对索引进行重建;
-- 重建SQL:
ALTER INDEX 索引名 REBUILD TABLESPACE 索引表空间名 STORAGE(INITIAL 初始值 NEXT 扩展值) NOLOGGING;
-- 重建后比较索引的Clustering Factor值有没有下降。
SELECT owner,index_name, clustering_factor, num_rows from dba_indexes WHERE owner='xxx' and index_name='xxx';
